Dlib – Comparing object detection between openCV tools and Dlib
Object detection is one of the regular algorithms that are needed while dealing with interactive robots. Ofcoarse, a wide variety of algorithms do exists, most of them being fine tuned implementation of Viola-Jones paper. Remaining are based on HOG feature dependent cascade classifiers for training data. With this post, I will be discussing and comparing two major algorithms for object detection mentioned above : Training using haar like feature with boosted cascade classifiers which I consider a openCV tool and Training using HOG feature based cascade classifier used in Dlib .
OpenCV tool for Object detection – Haar like feature based cascade classifiers
Quoting some important points from wikipedia:
Haar like features are digital image features used in object recognition. They owe their name to their intuitive similarity with Haar wavelets and were used in the first real-time face detector. Historically, working with only image intensities made the task of feature calculation computationally expensive. Viola and Jones adapted the idea of using Haar wavelets and developed the so-called Haar-like features. A Haar-like feature considers adjacent rectangular regions at a specific location in a detection window, sums up the pixel intensities in each region and calculates the difference between these sums. This difference is then used to categorize subsections of an image. For example, let us say we have an image database with human faces. It is a common observation that among all faces the region of the eyes is darker than the region of the cheeks. Therefore a common haar feature for face detection is a set of two adjacent rectangles that lie above the eye and the cheek region. The position of these rectangles is defined relative to a detection window that acts like a bounding box to the target object. This paper proposed by Viola – Jones in 2001 was so effective that even today object detectors are well tuned versions of their implementation.
When it comes to training, a classifier (namely a cascade of boosted classifiers working with haar-like features) is trained with a few sample views of a particular object , called positive examples, that are scaled to the same size, and negative examples – arbitrary images of the same size. Once the classifier is trained, it can be applied to testing image to ROI almost same scale or size to object. The classifier outputs a “1” if the ROI matches closely to trained object, and “0” otherwise. Here, to search for the object in whole image, sliding window paradigm is used . The classifier is designed such that the sliding window can be resized while searching for the object for the reason that object might be scaled up or down in image. This is usually a better option instead of scaling up whole image rather all time to match the sliding window scale with object. So, to find an object of an unknown size in the image the scan procedure should be done several times at different scales.
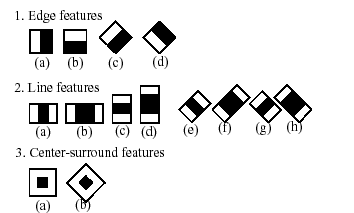
The word “cascade” in the classifier name means that the resultant classifier consists of several simpler classifiers (stages) that are applied subsequently to a region of interest until at some stage the candidate is rejected or all the stages are passed.
Enough of theory. Its time to code. OpenCV do provide example code and also useful training data in xml format. Generally the trained classifier is provided to algorithm with xml file, though other file options are also available. If you go through opencv repository, trained classifier is provided only for detecting face, eyes, upper body, lower body and complete body. No rigid objects like cars, juice box or something like that. You might have to google to get these classifiers from those who have already trained data for themselves, however, its doesn’t hold true for all objects around you. Some objects classifier might not be available and it would become necessary for you to train the data for yourself. This is something drawback for opencv’s object detection.
OpenCV comes with CascadeClassifier class which does the job of object detection. With simple use of only two functions within this class, the algorithm can be implemented
To summarize:
# Create an object from this class
# Load the xml file for required object detection into this instance with load()
# Use detectMultiScale() over the image after appropriate filtering, and collect he rectangular ROI from this function. This ROI must contain what object you were looking for
Easy? Lets have a look over the code from opencv documentation
#include "opencv2/objdetect.hpp"
#include "opencv2/highgui.hpp"
#include "opencv2/imgproc.hpp"
#include <iostream>
#include <stdio.h>
using namespace std;
using namespace cv;
/** Function Headers */
void detectAndDisplay( Mat frame );
/** Global variables */
String face_cascade_name = "haarcascade_frontalface_alt.xml";
String eyes_cascade_name = "haarcascade_eye_tree_eyeglasses.xml";
CascadeClassifier face_cascade;
CascadeClassifier eyes_cascade;
String window_name = "Capture - Face detection";
/** @function main */
int main( void )
{
VideoCapture capture;
Mat frame;
//-- 1. Load the cascades
if( !face_cascade.load( face_cascade_name ) ){ printf("--(!)Error loading face cascade\n"); return -1; };
if( !eyes_cascade.load( eyes_cascade_name ) ){ printf("--(!)Error loading eyes cascade\n"); return -1; };
//-- 2. Read the video stream
capture.open( -1 );
if ( ! capture.isOpened() ) { printf("--(!)Error opening video capture\n"); return -1; }
while ( capture.read(frame) )
{
if( frame.empty() )
{
printf(" --(!) No captured frame -- Break!");
break;
}
//-- 3. Apply the classifier to the frame
detectAndDisplay( frame );
int c = waitKey(10);
if( (char)c == 27 ) { break; } // escape
}
return 0;
}
/** @function detectAndDisplay */
void detectAndDisplay( Mat frame )
{
std::vector<Rect> faces;
Mat frame_gray;
cvtColor( frame, frame_gray, COLOR_BGR2GRAY );
equalizeHist( frame_gray, frame_gray );
//-- Detect faces
face_cascade.detectMultiScale( frame_gray, faces, 1.1, 2, 0|CASCADE_SCALE_IMAGE, Size(30, 30) );
for( size_t i = 0; i < faces.size(); i++ )
{
Point center( faces[i].x + faces[i].width/2, faces[i].y + faces[i].height/2 );
ellipse( frame, center, Size( faces[i].width/2, faces[i].height/2), 0, 0, 360, Scalar( 255, 0, 255 ), 4, 8, 0 );
Mat faceROI = frame_gray( faces[i] );
std::vector<Rect> eyes;
//-- In each face, detect eyes
eyes_cascade.detectMultiScale( faceROI, eyes, 1.1, 2, 0 |CASCADE_SCALE_IMAGE, Size(30, 30) );
for( size_t j = 0; j < eyes.size(); j++ )
{
Point eye_center( faces[i].x + eyes[j].x + eyes[j].width/2, faces[i].y + eyes[j].y + eyes[j].height/2 );
int radius = cvRound( (eyes[j].width + eyes[j].height)*0.25 );
circle( frame, eye_center, radius, Scalar( 255, 0, 0 ), 4, 8, 0 );
}
}
//-- Show what you got
imshow( window_name, frame );
}
This code is used for implementing face detection and eyes detection. As summarized above, first instances of class cascadeclassifier is launched and loaded with corresponding xml classifier file. Then it read the video stream and captures frame one by one to give it to function detectAndDisplay(). Now, within this function, image is filtered to bring out important feature with equalizeHist(). The openCV documentation has provided a tutorial for this, how does equalizing image histogram intensify important features from image. Finally, for face detection the function detectMultiScale() is launched which actually does the job of finding out object from image provided. The output is rectangular ROI which certainly holds positive for algorithm.
For eyes detection, simply this rectangular ROI are fed to detectMultiScale with eye detecting classifier file. This saves computation time from searching complete image for eyes rather and searching only within facial ROI. Finally circle and ellipses were sketched to show output to user.
Dlib’s tool for object detection – Using HOG feature based classifier for training.
Dlib do provide a separate trainer algorithm and a GUI as well to help you train the object detector all by yourself. This looks quite professional too, owing to presence of parameters which have to be fine tuned for trainer to detect objects at best. This was actually lacking in openCV toolset and hence I prefer using this library for objects whose trained classifiers might not be available on web. Moving on to process to code
First we need to build the GUI provided by Dlib. This is going to make further process easy.
Open Dlib->tools->imglab
This imglab once build will create a executable file for GUI. To build this GUI –
cd tools/imglab mkdir build cd build cmake .. cmake --build . --config Release
Once build, a executable file imglab will be created within the build folder.
Next, let’s assume you have a folder of images called /data/images. These images should contain examples of the objects you want to learn to detect. You will use the imglab tool to label these objects. Do this by typing the following
./imglab -c mydataset.xml /data/images
This will create a file called mydataset.xml which simply lists the images in /data/images. To annotate them run
./imglab mydataset.xml
A window will appear showing all the images. You can use the up and down arrow keys to cycle though the images and the mouse to label objects. In particular, holding the shift key, left clicking, and dragging the mouse will allow you to draw boxes around the objects you wish to detect. So next, label all the objects with boxes. Note that it is important to label all the objects since any object not labeled is implicitly assumed to be not an object we should detect.
Moreover, the other most important aspect not mentioned within commented lines of code is that you must draw the boxes will almost same aspect ratio and area close to 6400 pixels. I prefer to take this precaution beforehand since this creates a lot of mess when error occurs due to this restriction.
Once you finish labeling objects go to the file menu, click save, and then close the program. This will save the object boxes back to mydataset.xml. You can verify this by opening the tool again with
./imglab mydataset.xml
and observing that the boxes are present.
Now to keep the files organized, just copy the mydataset.xml to /data/images and move this folder to dlib->examples. Incase you further change the xml file save it to this new position of folder from save as option in GUI. This will avoid mess of copying things around.
Now coming to algorithm implementation train_object_detector.cpp , we can compile it using cmake just as we did with the imglab tool ( btw, it was already compiled incase you have followed by first post to this section for installing Dlib ). Once compiled, we can issue the command
./train_object_detector -tv mydataset.xml
which will train an object detection model based on our labeled data. The model will be saved to the file object_detector.svm. Once this has finished we can use the object detector to locate objects in new images with a command like
./train_object_detector some_image.png
This command will display some_image.png in a window and any detected objects will be indicated by a red box.
Easy huh ! Lets try it over as face detector. It is though advised by Dlib to implement a separate trainer fhog_object_detector.cpp which holds best detection for semi-rigid object like face, pedestrian, etc. Still, object detector do a pretty good job of detecting the face. Implement it yourself with this set of command lines,
./train_object_detector -tv examples/faces/training.xml -u1 --flip ./train_object_detector --test examples/faces/testing.xml -u1 ./train_object_detector examples/faces/*.jpg -u1
dlib provides a dataset for face detection to folder dlib/examples/faces. A important parameter used above is “–flip” which is recommended to be used when dealing with symmetric objects. This option doubles the dataset by flipping the images about vertical, that proves to better train the symmetric objects.
That’s all. I will be further discussing face landmark detection in next post. Please suggest Edits and comment doubts if you go through my posts, below in comment section.
for the object detector, how can I define a specific sliding window size? options.detection_windows_size = (460,1100) doesn’t seem to work
Hey Bogdan,
It would be great if you could give me a brief what are you trying to do and what libraries you are using. I will reply accordingly